Last time I wrote a blog post was almost ten years ago. I’m usually too busy to spend time on writing long articles, but the current LLM mania more or less forced me to write this. I already know this will bore some of you, and many will probably stop reading as soon as I start criticizing the so called “AI”, but if you stick with it, you’ll see this isn’t just a rant, I’ll also point out where I find LLMs are useful, not just where they suck.
The Code Generation Fallacy
Often people confuse code generation with problem solving. Imagine I build a mathematical formula generator and then tell the world that: “Math is basically solved, we can generate formulas instantly! Math is FREE now!”. Sure, we could generate every equation we know, plus endless variations of those, but is generating a bunch of symbols the same as doing mathematics? Is this how we were evaluated at school? Did you got an A for filling three pages with equations as fast as possible? Not really! You were given new problems that needed to be solved and the best solutions were: correct, elegant and often surprisingly short and if the solution showed a new perspective, it was even more valuable. Why was that? Because the value was not in the formulas you wrote on the paper but in the thinking behind it.
The fallacy is assuming that generating output is equivalent to solving the underlying problem.
Formulas are just a tool, a compact way to express reasoning. They exist because writing precise logic in plain English is insanely complicated. But the formula itself is not the solution: the idea behind it is.
The same applies to programming. Generating code is easy. You can produce hundreds of lines in seconds. But that doesn’t mean the problem is understood, or even correctly framed. Writing formulas is just a way to efficiently express your thoughts because writing them in natural language is just stupidly inefficient. That said, when we talk about “programming” with LLMs, we face three major problems: the Grammar Problem, the Noise Problem, and the Selection Problem.
The Grammar Problem
Even today, many devs consider that a computer science degree is useless for programming, but if you have one, you’ll most probably took a “Formal Languages” class that would actually teach you why a natural language such as English is a very poor way to express algorithms.
But let’s start a bit earlier, like a few centuries earlier. Early mathematics wasn’t written the way we know it today. Greek mathematicians like Euclid described proofs almost entirely in prose. A statement like: “The square on the hypotenuse is equal to the squares on the sides…” was written out in full sentences, no symbols, no equations.
For a long time, math was kind of stuck in this “rethorical stage” where everything was described in words . The shift to symbolic notation (Hindu-Arabic numerals, Leibnitz/Newton’s calculus notation) dramatically accelerated development because allowed compact, precise, manipulable expression. Once math moved from sentences to symbols, something changed fundamentally: expressions became shorter and reasoning became scalable. For example, instead of a paragraph, we now write:
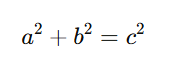
That’s not just shorter, it’s unambiguous and executable in your head. Try describing that same relationship in plain English with full rigor. You’ll need multiple sentences, and even then, interpretation creeps in. Math didn’t just evolve because people got smarter, it evolved because its language became precise.
And this isn’t unique to mathematics. Every science developed its own formal language: chemistry with molecular notation, physics with equations, and even the music with its notation system.
Imagine describing even a simple melody: rhythm, harmony, dynamics in plain English. It would take pages and still be ambiguous. Musical notation is far more precise, dense, and instrument-agnostic. A trained musician can read it and perform the piece accurately. And if you already know how to play, it’s obviously easier to just play the notes than to describe them. Ludwig van Beethoven composed Ode to Joy while deaf, and thankfully he wrote it in musical notation, if he had tried to describe it in words, we likely would have never heard the exact piece he had in mind.
Back to programming and the “Formal Languages” course, programming languages are deliberately designed formal gramars (context-free gramars in the Chomsky hierarky) that makes them: unanbiguous, mechanically parsable by compilers and interpreters, scalable to large complex system.
Natural languages like English are not context-free, are full of ambiguity, are context dependent. Chomsky’s hierarchy shows why computers handle formal languages well but struggle with the full richness (and messiness) of human language. That’s exactly why translating a precise intent from English prompts into correct code is lossy, the AI has to guess your meaning.
Almost every decade since the inception of programming, there’s been an attempt to replace programming with “easier” interfaces: visual drag-and-drop tools, English-like languages, pure diagram-based systems. Even Anders Hejlsberg explored ideas like this in the 90s but what we actually got was RAD: tools that make it easy to scaffold things like UI visually, but where the real logic still lives in a programming language. The same happened with WYSIWYG HTML editors like Adobe Dreamweaver: they worked to a point, but once you understood HTML, writing it directly was faster and clearer. Tools like Scratch, LabVIEW, or Microsoft Power Apps follow the same pattern: they are useful at small scales, but as complexity grows, precision gets harder and developers eventually return to code.
This happens because code is already the compressed, precise notation for algorithms, just like formulas are for math and notation is for music.
As a conclusion, if you already have a clear idea in your head, just like in music, physics, math, or chemistry, it’s simply easier to write it directly in code than to translate that idea into verbose English, only for an LLM to statistically and imprecisely reconstruct it in a programming language and then have to verify it.
The Noise Problem
Because prompts are written in natural language, which isn’t context-free, LLMs tend to overgeneralize, producing results that are close but not quite right, and sometimes completely off. Your intent gets buried under noise, and by noise, I don’t mean obvious garbage, but something much more dangerous: output that looks correct, sounds reasonable, but requires effort to verify.
Imagine you have 10 math problems to solve and instead of just solving them, you use an LLM to generate solutions. What do you get? A mix of correct and incorrect answers, some irrelevant formulas, some heuristic shortcuts instead of proper proofs, solutions that look convincing but don’t actually answer the question and sometimes even completely made-up formulas, delivered with confidence by the almighty AI.
Now, you’re no longer solving 10 problems, but you need to verify 10 potential solutions that may not even correspond to your actual problems and at the end, you might realize: Ohh, wait a minute… I still need to solve those 10 problem myself.
Verification is not free. In fact, it can be harder than solving the problem directly, because now you have to understand someone else’s reasoning, filter out irrelevant steps, check correctness, and detect subtle mistakes. To make things worse, LLMs are extremely good at producing wrong solutions that look deceptively correct.
I recently experienced this myself when I used AI to review a class and it returned 12 “bugs”. None of them were real. Some were vague style suggestions, some were hypothetical edge cases that didn’t apply, some were completely incorrect but: I spent hours going through them and while doing that, I missed two real, critical bugs! Any experienced developer would have spotted those in minutes, but noise doesn’t just waste time: it shifts your attention!
When output is cheap to generate, confident in tone and superficially plausible you end up in a situation where: the cost of verification exceeds the cost of creation. Instead of focusing on core logic, real constraints and actual problems you get pulled into checking irrelevant details, chasing false positives and validating things that didn’t need to exist in the first place. The AI didn’t just fail to help,it actively distracted me from the real issues.
This is the part most people underestimate: generating wrong code is obvious but generating plausible but unnecessary or misleading code is expensive and dangerous.
But why do the AI does this? Is it because it’s stupid? I mean is this something that can be “fixed” in the future? Is this a limitaiton of the current models? Well my friends… I have bad news..!
The Selection Problem
All the “noise” I talked about, while some of it is truly just noise, often they are solutions that are actually correct, just in a different context.
Due to the nature of the training data, regardless of how good it is, for almost any non-trivial problem you will find multiple correct solutions on the Internet: some more generic, some more concrete, some faster but less general, some more rigorous and some more practical depending on the context. The important point is that they are all correct in the right context.
But when you express your intent in English, the AI is forced to choose one of these and even if you are The Master of the Prompts and carefully think through what you want, translating that intent into English inevitably loses precision and omits context. Why? Re-read the Grammar Problem section above! We already know why. It has been studied for centuries. That is exactly why we developed formal notations across all sciences: so we can express solutions precisely and unambiguously, without relying on interpretation.
To mitigate the Selection problem, we started to write long .md files and increasingly large prompts: basically regressing to ancient times, when mathematics was taught in verbose natural language in old Greek texts. In the end, we end up writing more prompt text than we would have written code. The problem was already solved: USE THE DAMN FORMAL LANGUAGE!
The Sunk Cost Trap
Developers have a subtle but very real blind spot: once time has been invested into a solution, it becomes hard to admit it’s the wrong one. With LLMs, this shows up in a very specific way. You spend time crafting a prompt, refining it, rephrasing it, trying to “convince” the model to understand what you mean. Then the model gives you something that is close, but not quite right. You tweak it, adjust it, patch it. At some point, you know the code isn’t quite correct or at lest not the best approach, but instead of discarding it and writing the proper solution from scratch, you keep adapting it. Not because it’s the right solution, but because you’ve already invested time into generating it. The result is an “acceptable” solution that carries hidden flaws, while the actual optimal solution is often something you could have written faster and cleaner from the start.
So is AI always slower and useless?
No. In short, there are several places where LLMs actually shine and can significantly help.
1. Code scaffolding
The first case is when, with a small prompt, you can generate a lot of plausible code. Not logic, not solutions, but code.
Remember the previous chapters: if I already have the solution in my head, the easiest way to express it is often in code. This is true for the core logic, but in programming we often deal with repetitive plumbing code, and in those cases typing can become the bottleneck. What I mean is that once the solution is clear, the limiting factor is no longer thinking it through, but physically writing it down and LLMs a very good at that.
2. Learning and exploration
As I said: if you know how to play an instrument, it’s easier to just play it; and that’s true. I can play you some songs on the guitar, but I honestly can’t explain them in English. But what if you don’t really know how to play yet? Yes, you can search tutorials, documentation, or examples, but LLMs are very good at accelerating this phase and giving you statistically the best starting points to learn faster. For example: you are working with a new API, you are learning a new framework or language, you want to translate patterns from one language to another or you want quick example implementations… in these cases, the model acts like a fast “interactive reference,” helping you explore unfamiliar territory much faster than manual searching.
3. Summarization
I think this is the biggest and most overlooked aspect of LLMs. People assume AI is good at coding in the sense that you think of something, describe it in English, and the AI translates that into a detailed, correct implementation, as if it could read your mind and fill in all the missing logic. LLMs are actually suck at this. They’re heavily advertised for it, but really suck at it. What’s overlooked, though, and is often far more useful, is the opposite direction: LLMs are very good at taking large, complex code and summarizing it. And that might sound less impressive, but in practice it’s incredibly valuable. They can take massive, messy classes, highlight what matters, identify hotspots, suggest where problems might be, and generate reasonable documentation. It’s not perfect, but when you’re dealing with unfamiliar or legacy code, this is gold. Even with some inaccuracies, it can drastically reduce the time needed to build an initial mental model of the system.
Leave a Reply